Ziekenhuizen sluiten poliklinieken en spoedposten. Luchthavens kampen met enorme vertragingen. Streekvervoer in verschillende provincies rijdt niet omdat het contact met de alarmcentrale is verbroken. Veiligheidsregio’s zijn in rep en roer. Het hele betalingsverkeer in Australië ligt plat. En dat is slechts een greep uit de gevolgen van de CrowdStrike-storing van medio juli. Een korte storing, gelukkig, maar de financiële gevolgen waren enorm.
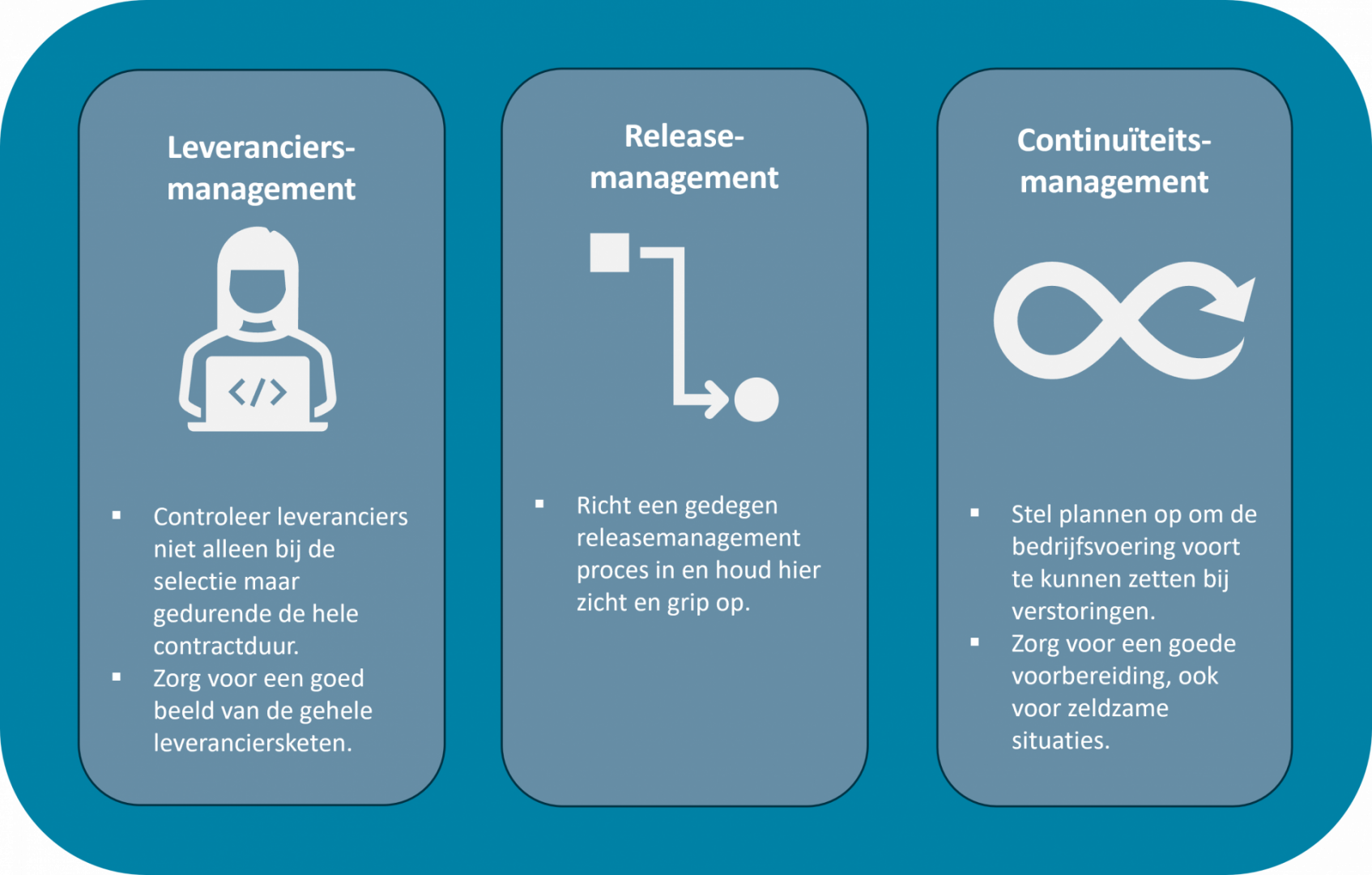
De storing was een probleem dat ontstond in de IT-systemen, maar de gevolgen ervan waren merkbaar voor zowel organisaties als de maatschappij. Het laat zien hoe afhankelijk we zijn van technologie voor onze dagelijkse processen, en nog belangrijker, hoe afhankelijk we zijn van de leveranciers van deze systemen. De mogelijkheid dat een dergelijke storing, met de daaropvolgende calamiteiten, opnieuw optreedt, kan niet worden uitgesloten. Kijk bijvoorbeeld naar de storing in het defensienetwerk amper een maand later. Dergelijke storingen kunnen leiden tot grote risico’s bij zorg- en overheidsorganisaties, die veel essentiële diensten leveren waarbij continuïteit van groot belang is. Daarom is het belangrijk om te leren van verstoringen die zich hebben voorgedaan. In deze blog focussen we op drie lessen van de CrowdStrike-storing: leveranciersmanagement, releasemanagement en continuïteitsmanagement.
Grip op de cyberketen
“CrowdStrike had er gewoon voor moeten zorgen dat haar product werkt,” was een veelgehoorde uitspraak tijdens de storing. “Zij is verantwoordelijk voor alle problemen die daarop volgden.” Hoewel deze opvatting niet geheel onwaar is, ligt het toch wat genuanceerder. De afnemer van de dienst kan, en moet, meer controle uitoefenen over haar leveranciers. Het is daarbij belangrijk om te begrijpen dat de veiligheid en betrouwbaarheid van diensten niet alleen afhankelijk zijn van de directe leveranciers, maar van alle schakels in de leveranciersketen. In onze ervaring zijn zorg- en overheidsorganisaties vaak wel kritisch bij het selecteren van leveranciers, maar zijn ze na de implementatie minder scherp op het regelmatig controleren en managen van deze leveranciers en de rest van de keten. En dat terwijl dit steeds essentiëler wordt, zoals collega Victor Meerloo eerder schreef in deze blog.
Hoe houd je grip op iets dat je hebt uitbesteed? Het is niet makkelijk om inzicht en controle te krijgen over de gehele leveranciersketen. Maar het is wel degelijk mogelijk! De eerste stap is het overzichtelijk maken van alle partijen in de keten. Vervolgens kun je, als organisatie, beleid opstellen waarin de afhankelijkheidsrelaties in kaart worden gebracht. Het is in elk geval belangrijk om helder te krijgen welke leveranciers essentieel zijn voor je dienstverlening, met hen goede afspraken te maken en deze afspraken regelmatig te controleren. Daarnaast is het van belang dat ketenleveranciers zelf ook goede afspraken maken met hún leveranciers. Als afnemer moet je op de hoogte worden gehouden van gecontracteerde ketenpartners, wijzigingen daarin, en andere relevante informatie. Hiermee kan er verder (samen) worden gewerkt aan het identificeren en managen van de risico’s in de keten. Het doel is uiteindelijk om de risico’s in de keten tot een acceptabel niveau te brengen.
Het belang van releasemanagement
Kijkend naar de CrowdStrike-storing, rijst de vraag of organisaties hadden kunnen voorkomen dat ze werden getroffen. Het korte antwoord is ja, maar ook hier is nuance belangrijk. Het draait allemaal om releasemanagement. Dit is het proces voor het plannen, beheren en controleren van softwareversies totdat ze in productie worden genomen, om ervoor te zorgen dat nieuwe functies en verbeteringen betrouwbaar en efficiënt worden uitgerold.
Er wordt vaak aangenomen dat de leverancier alle updates en patches grondig test, maar zoals we bij CrowdStrike hebben geleerd, kan dit soms misgaan. Leveranciers dwingen soms updates hard af, waarbij je als afnemer niet kan beslissen om een update wel of niet uit te voeren. Het is belangrijk om als ontvanger te weten welke updates dit zijn en welke zeggenschap je hierover hebt. Organisaties gaan er vaak vanuit dat ze zelf niet meer hoeven te testen omdat de leverancier dit zou doen. Toch blijkt dat het verstandig kan zijn om releases zelf te testen. Bij organisaties die hun ICT (grotendeels) uitbesteed hebben, ontbreekt het echter vaak aan de kunde en kennis om zelf updates goed te testen. Ook zorgt personeelstekort ervoor dat organisaties strategische keuzes moeten maken over de inzet van hun personeel.
Een andere manier om storingen door updates te voorkomen, is door bewust enkele dagen te wachten met het uitvoeren van de update. Dit vereist wel afspraken met de leverancier. Zo voorkom je dat eventuele problemen in de update jouw organisatie treffen, omdat je de update nog niet hebt uitgevoerd. Als blijkt dat de update succesvol is en geen storingen veroorzaakt, kun je deze met vertrouwen installeren, wetende dat deze veilig is. Het grote nadeel hiervan is echter dat je een update achterloopt en eventuele kwetsbaarheden nog niet hebt opgelost. Dit is weer een nieuw risico, waar je als organisatie een weloverwogen risico-afweging voor moet maken.
De CrowdStrike-storing: kritieke risico's en de rol van de kernel
De aard van de CrowdStrike-update bracht een aanzienlijk inherente risicofactor met zich mee, die niet mag worden onderschat. De Falcon-sensor van CrowdStrike opereert namelijk op het hoogste niveau van systeemintegratie, met directe toegang tot de kernel van het besturingssysteem. De kernel vormt het fundament van het systeem, waarbij het fungeert als het centrale coördinatiepunt voor hardware-interacties en softwareprocessen. Elke wijziging of interventie op dit niveau van het besturingssysteem brengt potentiële risico's met zich mee, aangezien de kleinste fout of afwijking verstrekkende gevolgen kan hebben voor de stabiliteit en veiligheid van het hele systeem. Dit werd pijnlijk duidelijk toen de recente update van CrowdStrike onverwachte complicaties veroorzaakte. Vanwege de kritieke rol die de kernel speelt, had de update van CrowdStrike daarom van begin af aan als risicovol moeten worden geclassificeerd en onderworpen moeten worden aan extra voorzorgsmaatregelen, zoals bijvoorbeeld snapshots of back-ups. Het is essentieel dat updates die toegang hebben tot zulke gevoelige en cruciale delen van een systeem, zoals de kernel, standaard als potentieel gevaarlijk worden bestempeld en met de grootste zorg worden uitgerold.
Voorbereiding op continuïteit
Een scenario zoals de storing bij CrowdStrike is zeldzaam, maar de impact is enorm. Wanneer één leverancier in de keten een probleem veroorzaakt, werkt dit als een cascade verder door de keten, tot in de primaire bedrijfsvoering van organisaties en daarbuiten. De vraag is eerder wanneer er een soortgelijk incident plaatsvindt dan of er een zal plaatsvinden. Om een dergelijke verstoring van de maatschappij, zoals die in juli, of erger, te voorkomen, moeten organisaties zich voorbereiden om primaire processen draaiende te houden. In andere woorden: continuïteitsmanagement. Dit betekent dat organisaties een plan moeten hebben om operationeel te blijven, zelfs bij een storing die de bedrijfsvoering hindert.
Bedrijfscontinuïteitsmanagement (BCM) is een systematische aanpak die organisaties helpt de impact van verstoringen te minimaliseren en essentiële functies tijdens een crisis te behouden. Het begint met het identificeren van potentiële bedreigingen en het evalueren van de gevolgen voor de bedrijfsvoering, waarna robuuste strategieën kunnen worden ontwikkeld om de continuïteit van de organisatie te waarborgen. BCM gaat verder dan alleen IT-systemen herstellen of een back-up plan hebben; het omvat alle aspecten van de primaire bedrijfsvoering. Met een goed uitgevoerd BCM-plan kan een organisatie snel reageren op incidenten, de schade beperken en de normale activiteiten zo snel mogelijk hervatten.
In een tijdperk waarin incidenten zoals de storing bij CrowdStrike steeds waarschijnlijker worden, is een effectief BCM-plan essentieel om bedrijfsverstoringen te voorkomen en de stabiliteit van de organisatie en haar partners te waarborgen. In de praktijk zien we dit al regelmatig:
- Zorgorganisaties hebben twee mogelijkheden om medicatielijsten uit te lezen zodat ze altijd up-to-date medicatie informatie hebben.
- Veiligheidsregio’s hebben bijvoorbeeld een back-up meldkamer wanneer de reguliere meldkamer niet beschikbaar is.
Overigens moet hier ook een risico-afweging worden gemaakt; van sommige processen kan je accepteren dat ze tijdelijk stilliggen omdat de financiële organisatorische en menselijke impact beperkt is.
Ook hele grote organisaties, zoals Microsoft, kunnen op een gegeven moment onbereikbaar worden door een storing. Hoewel de kans klein is, kan de impact hiervan enorm zijn, vooral omdat veel bedrijven en instellingen afhankelijk zijn van hun diensten en producten. De Crowdtrike-storing toont dit ook aan. Niemand had een storing van deze aard voorzien. Het is daarom essentieel om ook deze risico's op te nemen in het continuïteitsplan. Door deze potentiële verstoring in het risico-overzicht mee te nemen, kunnen organisaties voorbereid zijn op scenario's waarin zelfs de grootste en meest betrouwbare leveranciers onverwacht uitvallen. Dit maakt ze beter bestand tegen onverwachte tegenslagen en waarborgt de continuïteit van de bedrijfsvoering onder alle omstandigheden.
De les van de CrowdStrike-storing
De storing bij CrowdStrike heeft pijnlijk duidelijk gemaakt hoe kwetsbaar moderne organisaties zijn voor verstoringen in hun IT-systemen. Het incident benadrukt de cruciale rol van leveranciersmanagement, releasemanagement en continuïteitsmanagement in het beschermen van bedrijfsprocessen en het waarborgen van stabiliteit. Organisaties moeten proactief zijn in het beheren van hun leveranciersketen, releasemanagement, en het voortzetten van de primaire processen tijdens crises. Alleen door deze maatregelen serieus te nemen, kunnen ze de impact van toekomstige incidenten minimaliseren en hun operationele continuïteit waarborgen. Het is niet voldoende om te vertrouwen op technologie; organisaties moeten verantwoordelijkheid nemen voor het beheersen van de risico's die gepaard gaan met afhankelijkheid van externe partijen.
Ben je benieuwd hoe we je verder kunnen helpen in het kader van leveranciersmanagement, releasemanagement en continuïteitsbeheer? Neem contact op en dan zullen we samen je vraag verkennen!
