Ik moet een jaar of vijftien zijn als mijn vader zich opsluit in zijn studeerkamer. Dagenlang brengt hij er door, in zijn eentje, hardop pratend tegen niemand. Het zijn de jaren negentig en mijn vader heeft FreeSpeech aangeschaft: software met heuse kunstmatige intelligentie erin die ervoor gaat zorgen dat hij met zijn PC kan praten. Een droom! Nooit meer met twee vingers typen of eindeloos in menu’s naar het juiste knopje zoeken. Voortaan hoeft hij maar te zeggen wat hij wil en dan voert de computer al zijn wensen uit. Het loopt anders dan hij denkt...
Tegenwoordig zit spraakherkenning standaard in tekstverwerkers. Computers kunnen ook terugpraten, teksten samenvatten, muziek maken of illustraties. Maar hoe werkt dat eigenlijk? Waarom lukt nu wel wat nog niet zolang geleden onmogelijk leek? Of, anders gezegd: waarom heeft het zolang geduurd?
Het probleem met katten
Van computers zijn we gewend dat ze beschikken over bovenmenselijke vaardigheden. Ze kunnen complete encyclopedieën onthouden en ze foutloos opdreunen. In een fractie van een seconde voeren ze berekeningen uit die de slimste mens tot wanhoop zou drijven. Aan de andere kant hebben ze de grootste moeite met allerlei zaken die voor mensen een peulenschil zijn.
Neem nu het kattenprobleem. De meeste mensen leren als dreumes het verschil tussen een Woef en een Miauwmiauw. Maar computers konden heel lang niet zien of een er kat op een foto stond of niet. Waar wij in een oogopslag een poes herkennen, of juist een konijn, een vrachtschip of een boterham met pitjeskaas, liepen computers daar compleet op stuk. En dat heeft alles te maken met de manier waarop we ze programmeren.
Een pak kaarten sorteren
Om iets te doen, heeft een computer een stappenplan nodig met instructies nodig die heel precies beschrijven wat er wanneer moet gebeuren. Als zo’n stappenplan een bepaald probleem kan oplossen, noemen we het een algoritme. Een klassiek voorbeeld dat je overal terugziet, is sorteren. We gebruiken het om e-mails op volgorde van binnenkomst te zetten, of een lijst namen op alfabet.
Of om een pak kaarten te sorteren. Een eenvoudig algoritme daarvoor ziet er zo uit:
Herhaal deze stappen even vaak als er kaarten zijn:
Neem de voorste kaart.
Is deze kaart groter dan de volgende?
Ja: verwissel de twee kaarten.
Nee: doe niets.
Ga naar de volgende kaart.
In een echt programma zijn de stappen veel kleiner en staan de instructies vol jargon en haakjes en puntkomma’s - maar dit geeft een aardig beeld.
Een kattenalgoritme
Stel dat je een algoritme wil schrijven dat katten herkent. Hoe pak je dat aan? Misschien begin je met iets als dit:
Heeft-ie vier poten?
Heeft-ie ovaalvormige pupillen?
Heeft-ie snorharen?
Heeft-ie een T-vormige neus?
Heeft-ie een vacht?
...
Zoals je merkt, is het lastig om precieze regels op te stellen voor wat wel en geen kat is. Bovendien zijn er altijd uitzonderingen te bedenken. Want wat als je kat stoned is?

Hoezo, ovale pupillen?
Of wat te denken van het haarloze Donskoy ras?

Welke vacht?
Daar komt bij dat een computer niet ziet zoals wij dat doen. Een foto is voor een computer niets anders dan een lange reeks enen en nullen. Om daar poten in te ontdekken - of snorharen, of een vacht - is net zo moeilijk als er een complete kat in te zien. Dus op deze manier verschuiven we het probleem alleen maar.
De computer op puppycursus
We hebben een andere kijk op programmeren nodig. In plaats van alles voor te kauwen, laten we een algoritme leren wat de bedoeling is. De methode lijkt op hoe je een hond leert zitten.
Daarvoor heb je een flinke voorraad koekjes nodig. Je laat je hond voor je staan. Je zegt ‘Zit!’ en dan beweeg je een koekje over zijn kop. De hond volgt het koekje met zijn blik en gaat daarom vanzelf zitten.

Dan geef je hem het koekje en je prijst hem. ‘Braaf!’ Dit herhaal je net zolang tot hij het snapt. Na een poosje heb je geen koekje meer nodig: een korte handbeweging of het commando geven is voldoende om je hond te laten zitten (tenzij het om mijn hond gaat die verse paardenmest op het spoor is om eens flink in te rollen).
Lerende machines
Veel AI werkt op dezelfde manier. We beginnen met een dom algoritme. Op basis van een foto, roept het een getal tussen de 0 en 1. In eerste instantie is dat getal willekeurig, maar het moet aangeven of er een kat op de foto staat, of juist niet.

In dit geval is het algoritme 60% zeker van zijn zaak. Het juiste antwoord was 100% geweest, dus geven we terug dat hij 40% te laag zat. Het algoritme past zichzelf op basis van die feedback een heel klein beetje aan, net genoeg om de volgende keer dat hij deze foto ziet, iets dichter bij het goede antwoord te zitten.
Dit proces herhalen we met andere foto’s waar soms wel, soms geen kat op staat. Elke keer maakt het algoritme zichzelf een heel klein beetje beter. Na duizend keer kan het heel aardig katten herkennen. Na honderdduizend keer is hij er best goed in en na een miljoen plaatjes krijg je hem niet snel meer gek.
Dat werkt niet alleen voor het herkennen van katten op foto’s, maar voor allerlei patronen. Handschriften lezen, spraak herkennen, röntgenfoto’s interpreteren, reclames selecteren, je smaak in liedjes of televisieseries begrijpen of creditcardfraude detecteren: het is allemaal gebaseerd op algoritmes die op deze manier getraind zijn.
Een algoritme om een algoritme te trainen
Het trainen van een algoritme is saai en repetitief werk. En als er iets is waar computers goed in zijn, dan is het in saai en repetitief werk. Dus besteden we dat uit aan een tweede algoritme: een docent die het leerlingalgoritme traint in het herkennen van katten.
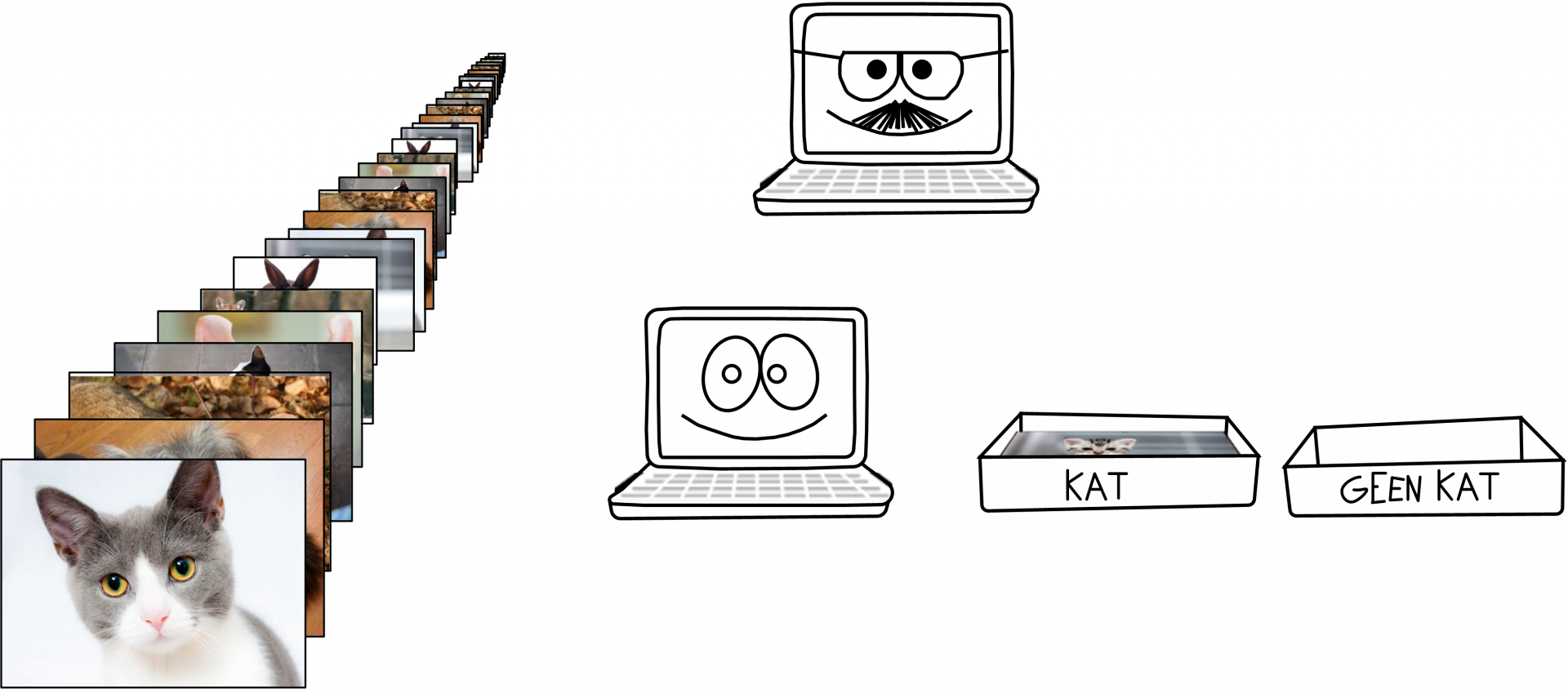
Natuurlijk heeft de docent zelf geen idee wat er op de plaatjes staat – anders zouden we niet zoveel moeite in de leerling hoeven steken. Daarom geven we hem bij elk plaatje het juiste antwoord, zodat hij de leerling feedback kan geven.
Je computer praat terug
Moderne AI kan meer dan patronen herkennen. Het kan ook nieuwe dingen creëren. Dat gaat met ongeveer dezelfde techniek. Onder praatprogramma’s zoals ChatGPT gaat een taalmodel schuil dat niet getraind is met foto’s, maar met enorme lappen tekst.
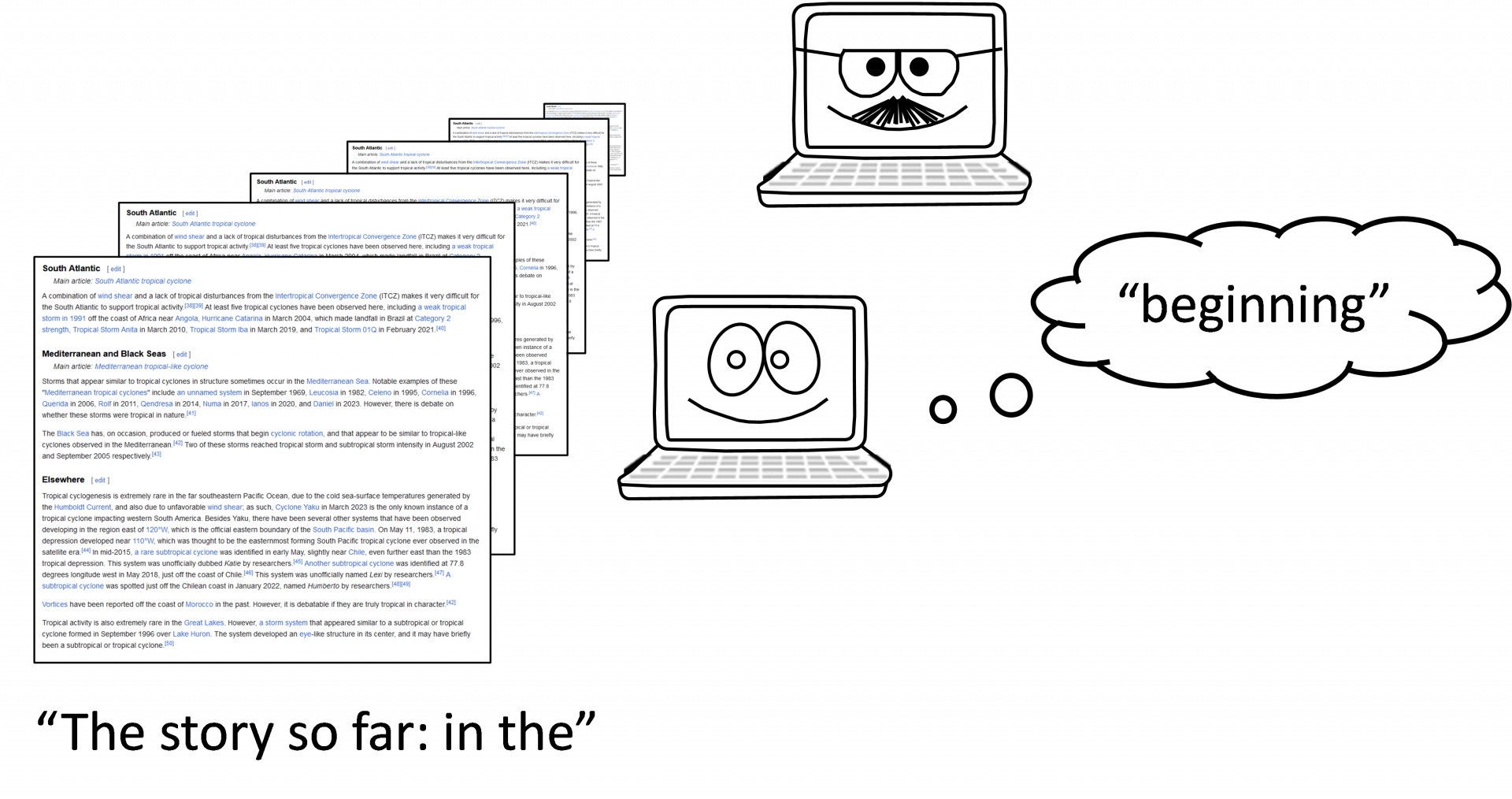
Deze docent toont steeds een stukje van een tekst en vraagt de leerling het volgende woord te voorspellen. Grotere taalmodellen verslinden tientallen miljoenen boeken om te leren op commando tekst te produceren. Omdat de wereld niet zit te wachten op nog meer mansplainers, worden ze daarna nog een keer getraind, dit keer met voorbeelden van gesprekken. En zo leren ze chatten.
Meer! Meer! Meer!
Om algoritmes op deze manier te trainen, zijn trainingsdata nodig. Heel veel trainingsdata. AI-bedrijven halen veel ruwe data van het internet en laten die door (slecht betaalde) mensen controleren en aanvullen: hier staat wel een kat op, hier niet. Of ze gebruiken hun klanten om, vaak onbewust, data te verzamelen. Sommige autofabrikanten verzamelen de beelden die de camera’s van hun auto’s maken terwijl ze rondrijden.
Data alleen zijn niet genoeg voor goede prestaties. Het hart van lerende algoritmes bestaat uit statistische modellen. Hoe groter het model, hoe meer data het kan gebruiken en hoe beter het werkt. Daarom worden ze steeds groter en daarom is voor het trainen van zulke algoritmes steeds meer rekenkracht nodig. Dat kost veel energie - niet voor niets tonen technologiebedrijven belangstelling om eigen kerncentrales uit te baten.
Verhaaltjes voorlezen aan je computer
Terug naar de jaren negentig, wanneer mijn vader in zijn studeerkamer probeert FreeSpeech aan de praat te krijgen. Om de stem van zijn gebruiker te leren herkennen, heeft het algoritme trainingsdata nodig. Vandaar dat de leverancier een boek van honderd pagina’s mee heeft gestuurd, waaruit mijn vader aan zijn computer voorleest. Eerst nog kalm en vastberaden, later luider en een stuk minder kalm. Er klinken steeds vaker woorden die niet in de officiële tekst staan. Na drie dagen praten is hij zijn stem kwijt en begrijpt zijn PC hem nog altijd niet.
Te weinig data, een te klein algoritme en te weinig rekenkracht maakten dat zijn pogingen van begin af waren gedoemd te mislukken. Op het moment zelf wist hij het niet, maar mijn vader was zijn tijd ver vooruit.
En nu?
Vandaag de dag steken bedrijven en hun investeerders miljarden in de ontwikkeling van AI. Dat geld moet een keer worden terugverdiend en dus vliegen de verhalen over wereldveranderende toepassingen ons om de oren. Als we Silicon Valley mogen geloven, ligt het eeuwige leven voor het grijpen en zal ChatGPT binnenkort klimaatverandering oplossen. Sceptici wijzen erop dat AI plaatjes genereert van katten met vijf poten, struikelt over simpele rekensommen en niets van de echte wereld lijkt te begrijpen.
En inderdaad: kunstmatige intelligentie mist vooralsnog gezond verstand. Toch is dat geen reden om AI dan maar af te doen als modegril, daarvoor zijn de mogelijkheden te groot. Volg dus vooral de ontwikkelingen, experimenteer ermee, leer ervan, maar houd altijd een korreltje zout bij de hand.

